
도찐개찐
[머신러닝-비지도] 04. Hierarchical clustering 본문

Hierarchical clustering
(한글 : 계층적 군집 분석) 은 비슷한 군집끼리 묶어 가면서 최종 적으로는 하나의 케이스가 될때까지 군집을 묶는 클러스터링 알고리즘이다.
ex)
“진돗개,세퍼드,요크셔테리어,푸들, 물소, 젖소" 를 계층적 군집 분석을 하게 되면
첫번째는 중형견, 소형견, 소와 같은 군집으로 3개의 군집으로 묶일 수 있다.

이를 한번 더 군집화 하게 되면 [진돗개,셰퍼드] 와 [요크셔테리어,푸들] 군집은 하나의 군집(개)로 묶일 수 있다.

마지막으로 한번 더 군집화를 하게 되면 전체가 한군집(동물)으로 묶이게 된다.

이렇게 단계별로 계층을 따라가면서 군집을 하는 것을 계층적 군집 분석이라고 한다.
계층적 군집 분석은 Dendrogram이라는 그래프를 이용하면 손쉽게 시각화 할 수 있다.
(출처 : https://bcho.tistory.com/1204)

계층적 군집


- 군집트리, 덴드로그램을 생성하여 다양한 데이터를 그룹화
- 비슷한 군집끼리 묶어 가면서 최종적으로 하나의 군집단으로 묶는 기법
- 즉, 군집간의 거리를 기반으로 군집화하는 방식으로
- 기존의 군집기법(kmeans)에 비해 군집수를 지정x
- 계층적 군집의 종류
- 응집형bottom-up : 개별데이터 군집 => 군집단 형성
- 분리형top-down : 데이터 전체를 하나의 군집 => 세부적으로 여러 군집으로 나눔
응집형 군집의 예
import mglearn
mglearn.plots.plot_agglomerative_algorithm()
덴드로그램 시각화
- 각 개체들이 결합되는 순서를 나타내는 트리형태의 다이어그램
-

-

- linkage 함수의 method 속성으로 각 군집간의 연결방식을 지정
- single/average/complete/centeroid/ward
- 최단연결single : 각 군집을 대상으로 최소거리 기준 (가까운것부터 군집)
- 평균연결average : 각 군집을 대상으로 평균거리 기준
- 최장연결complete : 각 군집을 대상으로 최대거리 기준 (먼것부터 군집)
- 중심연결centeroid : 각 군집내 중심점 기준
- 와드연결ward : 군집간 SSW(응집도), SSB(분리도)간의 차이를 이용(일정한 크기의 군집)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsX = np.array([ [5,3], [10,5], [15,12],
[24,10], [30,30], [85,70],
[71,80], [60,78], [70,55],
[80,91] ])
plt.plot(X[:, 0], X[:, 1], 'ro')[<matplotlib.lines.Line2D at 0x7fafa2e3cbe0>]
from scipy.cluster.hierarchy import dendrogram
from scipy.cluster.hierarchy import linkage, fcluster
# 거리계산방식 지정
linked = linkage(X, method='single')덴드로그램 시각화
- dendrogram(연결방식, 옵션)
dendrogram(linked, orientation='top')
plt.ylabel('distance') # 군집간 거리
plt.xlabel('instance') # 개체
plt.axhline(20, color='red', linestyle='--')
plt.show()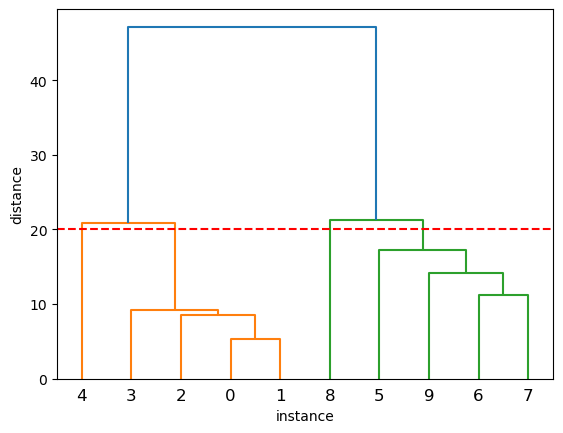
적절한 군집수 알아보기
- 덴드로그램을 보고 n개의 군집을 나눌려고 할때
적절한 distance는 어떻게 알아볼까? - 덴드로그램에서 밑에서 위로 올라갈수록
군집을 의미하는 선의 갯수가 줄어둠 (응집형 군집!) - scipy에서는 fcluster함수를 이용해서
distance가 특정값일때 군집정보를 알려줌- fcluster(연결방식, 거리, 거리측정방식)
# 군집간 거리가 20일때 군집의 수는?
clusters = fcluster(linked, 20, criterion='distance')
clustersarray([1, 1, 1, 1, 2, 3, 3, 3, 4, 3], dtype=int32)# unique : 중복값 제외하고 한번만 카운트 하는 함수
np.count_nonzero(np.unique(clusters))4iris를 이용한 계층형 군집 분석
- AgglomerativeClustering(군집수, 거리측정방식, 연결방식)
- affinity : 거리측정방식 (euclidean, mahattan, cosine등)
from sklearn.datasets import load_irisiris = load_iris()
# linked = linkage(iris.data, method='single')
# linked = linkage(iris.data, method='complete')
# linked = linkage(iris.data, method='average')
linked = linkage(iris.data, method='ward')
# linked = linkage(iris.data, method='centroid')
plt.figure(figsize=(25,10))
dendrogram(linked, orientation='top', leaf_font_size=11, leaf_rotation=0)
plt.ylabel('distance') # 군집간 거리
plt.xlabel('instance') # 개체
plt.axhline(6.5, color='red', linestyle='--')
plt.show()
# 군집간 거리측정방식을 ward로 했을때 3개 군집으로 나눌 경우
# 군집간 거리는?
clusters = fcluster(linked, 6.7, criterion='distance')
clusters
# unique : 중복값 제외하고 한번만 카운트 하는 함수
np.count_nonzero(np.unique(clusters))3iris를 이용한 응집형 군집 분석
- AgglomerativeClustering(군집수, 거리측정방식, 연결방식)
from sklearn.cluster import AgglomerativeClustering
groups = AgglomerativeClustering(n_clusters=3,
affinity='euclidean', linkage='ward'
)
groups.fit(iris.data)AgglomerativeClustering
AgglomerativeClustering(n_clusters=3)groups.labels_array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2,
2, 2, 2, 0, 0, 2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 2, 0, 0, 2, 2, 2, 2,
2, 0, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 0])# from yellowbrick.cluster import SilhouetteVisualizer
# from yellowbrick.cluster import KElbowVisualizer# 실루엣 계수 확인
from sklearn.metrics import silhouette_score
silhouette_score(iris.data[:, [0, 1]], groups.labels_)0.3576978019804449# 실루엣 계수 확인
from sklearn.metrics import silhouette_score
silhouette_score(iris.data[:, [2, 3]], groups.labels_)0.6398270745578704data = iris.datafrom yellowbrick.cluster import SilhouetteVisualizer
from sklearn.cluster import KMeans# ax[행][열] : 그래프 출력 위치 지정
# https://matplotlib.org/stable/gallery/subplots_axes_and_figures/subplots_demo.html
fig, ax = plt.subplots(2, 3, figsize=(15, 8))
for i in [2, 3, 4, 5, 6, 7]:
ac = AgglomerativeClustering(n_clusters=i, affinity='euclidean', linkage='ward')
q, mod = divmod(i, 3)
visualizer = SilhouetteVisualizer(ac, ax=ax[q-1][mod])
visualizer.fit_predict(data)
sss = []
for k in range(2, 10+1):
ac = AgglomerativeClustering(n_clusters=k, affinity='euclidean', linkage='ward')
ac.fit(data)
ss = silhouette_score(data, ac.labels_, metric='euclidean')
sss.append(ss)plt.plot(range(2, 10 + 1), sss, 'ro--')
plt.show()
from yellowbrick.cluster import KElbowVisualizer
ac = AgglomerativeClustering()
visualizer = KElbowVisualizer(ac, k=(1, 10), timings=False)
visualizer.fit(data) estimator=AgglomerativeClustering(n_clusters=9), k=(1, 10),
timings=False)</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-2" type="checkbox" ><label for="sk-estimator-id-2" class="sk-toggleable__label sk-toggleable__label-arrow">KElbowVisualizer</label><div class="sk-toggleable__content"><pre>KElbowVisualizer(ax=<AxesSubplot:>,
estimator=AgglomerativeClustering(n_clusters=9), k=(1, 10),
timings=False)</pre></div></div></div><div class="sk-parallel"><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-3" type="checkbox" ><label for="sk-estimator-id-3" class="sk-toggleable__label sk-toggleable__label-arrow">estimator: AgglomerativeClustering</label><div class="sk-toggleable__content"><pre>AgglomerativeClustering(n_clusters=9)</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-4" type="checkbox" ><label for="sk-estimator-id-4" class="sk-toggleable__label sk-toggleable__label-arrow">AgglomerativeClustering</label><div class="sk-toggleable__content"><pre>AgglomerativeClustering(n_clusters=9)</pre></div></div></div></div></div></div></div></div></div></div>
visualizer = KElbowVisualizer(ac, k=(2, 10), metric='silhouette', timings=False)
visualizer.fit(data)
visualizer.show()findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Generic family 'sans-serif' not found because none of the following families were found: Arial, Liberation Sans, Bitstream Vera Sans, sans-serif
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Generic family 'sans-serif' not found because none of the following families were found: Arial, Liberation Sans, Bitstream Vera Sans, sans-serif
ac = AgglomerativeClustering(n_clusters=k, affinity='euclidean', linkage='ward')visualizer = KElbowVisualizer(ac, k=(2, 10), timings=False)
visualizer.fit(data)
visualizer.show()
농구선수 게임데이터를 이용해서 포지션 군집 분석
bbp = pd.read_csv('../data/bbplayer.csv')
data = bbp.iloc[:, 2:8]
linked = linkage(data, method='ward')
bbp.head()| Player | Pos | 3P | 2P | TRB | AST | STL | BLK | |
|---|---|---|---|---|---|---|---|---|
| 0 | Alex Abrines | SG | 1.4 | 0.6 | 1.3 | 0.6 | 0.5 | 0.1 |
| 1 | Steven Adams | C | 0.0 | 4.7 | 7.7 | 1.1 | 1.1 | 1.0 |
| 2 | Alexis Ajinca | C | 0.0 | 2.3 | 4.5 | 0.3 | 0.5 | 0.6 |
| 3 | Chris Andersen | C | 0.0 | 0.8 | 2.6 | 0.4 | 0.4 | 0.6 |
| 4 | Will Barton | SG | 1.5 | 3.5 | 4.3 | 3.4 | 0.8 | 0.5 |
plt.figure(figsize=(25,10))
dendrogram(linked, orientation='top', leaf_font_size=10, leaf_rotation=90)
plt.ylabel('distance') # 군집간 거리
plt.xlabel('instance') # 개체
plt.show()
ac = AgglomerativeClustering(affinity='euclidean', linkage='ward')visualizer = KElbowVisualizer(ac, k=(2,7), metric='silhouette', timings=False)
visualizer.fit(data)
visualizer.show()
<AxesSubplot:title={'center':'Silhouette Score Elbow for AgglomerativeClustering Clustering'}, xlabel='k', ylabel='silhouette score'>visualizer = KElbowVisualizer(ac, k=(2,7), metric='calinski_harabasz', timings=False)
visualizer.fit(data)
visualizer.show()
ac = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
ac.fit(data)plt.scatter(data.iloc[:, 1], data.iloc[:, 2], c=ac.labels_, cmap='tab10')
plt.show()
728x90
'PYTHON > 데이터분석' 카테고리의 다른 글
| [머신러닝-마이닝] 06. KoNLPy (0) | 2023.01.04 |
|---|---|
| [머신러닝-마이닝] 05. 텍스트 마이닝 (0) | 2023.01.04 |
| [머신러닝-비지도] 03. dendrogram (0) | 2023.01.04 |
| [머신러닝-비지도] 02. k-means (0) | 2023.01.04 |
| [머신러닝-비지도] 01. 군집분석 (0) | 2023.01.04 |
'PYTHON/데이터분석' Related Articles
more




Comments