
도찐개찐
[머신러닝-비지도] 02. k-means 본문
머신러닝의 종류
- 지도학습 - 데이터와 정답을 이용해서 패턴/규칙 파악
- 비지도 학습 - 데이터만을 이용해서 유사도에 따른 패턴/규칙 파악
- 비지도학습의 대표적인 분석방법 : 군집
k-means
- 서로 유사성이 높은 것끼리 관측값을 묶어 다수의 그룹으로 만듦
- 즉, 동일 그룹내 구성원간의 유사성은 높지만 다른 그룹의 구성원과의 유사성은 거의 없도록 하는 것
- 군집분석 SSW, SSB
- prototype based 군집 - 여러번 시도후 완성
- 각 군집이 처음부터 완성(고정)되어 있는 것은 아니고
군집화 시도 횟수에 따라 군집의 유형이 변함
- 각 군집이 처음부터 완성(고정)되어 있는 것은 아니고
- 활용분야
- 소비자유형 파악 - 타겟 마케팅 적용
- 범죄율이 높은 지역 검출
- 이미지/얼굴/손글씨 인식 - SVM
- 유전자 검사/지리정보를 이용해서 지형 탐사
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns### kmeans 알고리즘 이해하기
x = [7,2,6,3,6,5,3,1,5,7,7,2]
y = [8,4,4,2,5,7,3,4,4,7,6,1]
plt.scatter(x, y, color='red')
plt.grid()
유사도 파악
- k-means 에서는 각 점간의 거리로
- 비슷한 특성을 가지는 데이터를 묶음
- 따라서, 유사도 측정을 위해 임의의 기준점centeroid 선정
- 기준점과 각 점간의 거리 계산
- 유클리드 거리 계산법 이용
- 즉, A(x1, y1), B(x2, y2) 간의 거리 계산은
sqrt((x2-x1)^2 + (y2-y1)^2) 로 함
# C1, C2 = (1,5), (6,8)
plt.plot(x, y, 'ro')
plt.plot([1,6], [6,8], 'bX')
plt.grid(True)
import math
# P(5,7)은 c1 또는 c2 분류 될지 알아 봄
# c1(1,5) c2(6,8)
# p(5,7) 4.47 1.41
print('p -> c1', math.sqrt((1-5)**2 + (5-7)**2))
print('p -> c2', math.sqrt((6-5)**2 + (8-7)**2))p -> c1 4.47213595499958
p -> c2 1.4142135623730951# P(6,4)는 c1또는 c2로 분류 될지 알아봄
print('p -> c1', math.sqrt((1-6)**2 + (5-4)**2))
print('p -> c2', math.sqrt((6-6)**2 + (8-4)**2))p -> c1 5.0990195135927845
p -> c2 4.0# P(2,4)는 c1또는 c2로 분류 될지 알아봄
print('p -> c1', math.sqrt((1-2)**2 + (5-4)**2))
print('p -> c2', math.sqrt((6-2)**2 + (8-4)**2))p -> c1 1.4142135623730951
p -> c2 5.656854249492381새로운 기준점 선정
- 모든 데이터에 대한 군집화가 수행된 후
- 새로운 센터노이드를 선정한 후 다시 유사도에 의한 군집 실시
- 새로운 센터노이드를 선정하는 방법은 각 군집별 평균값을 이용
- 즉, 군집 C1, C2의 각 X, Y 좌표간의 평균 계산
# C1의 새로운 센터노이드 지정
# 새로운 x좌표 : 1,2,2,3,3 / 5 = 2.2
# 새로운 y좌표 : 1,2,3,4,4 / 5 = 2.8
# C2의 새로운 센터노이드 지정
# 새로운 x좌표 : 5,5,6,6,7,7,7 / 7 = 6.14
# 새로운 y좌표 : 4,4,5,6,7,7,8 / 7 = 5.85
plt.plot(x, y, 'ro')
plt.plot([2.2, 6.14], [2.8, 5.85], 'bX')
plt.grid(True)
### iris 데이터 셋을 이용해 군집 분석
from sklearn.datasets import load_iris
from sklearn.cluster import KMeansiris = load_iris()
data = iris.data
target = iris.target# n_clusters : 나누려고 하는 군집 갯수
# algorithm : 군집시 사용하는 거리 계산 알고리즘
kms = KMeans(n_clusters=3, random_state=2208301540)
kms.fit(data)KMeans(n_clusters=3, random_state=2208301540)On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KMeans(n_clusters=3, random_state=2208301540)군집 결과 확인하기
- 군집 결과는 labels_ 에 저장
kms.labels_array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 2, 2, 2, 1, 2, 2, 2,
2, 2, 2, 1, 1, 2, 2, 2, 2, 1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 2, 2, 2,
2, 1, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 1], dtype=int32)from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
confusion_matrix(target, kms.labels_)array([[50, 0, 0],
[ 0, 48, 2],
[ 0, 14, 36]])accuracy_score(target, kms.labels_)0.8933333333333333실루엣/엘보우 계수
- iris 데이터셋 경우, 각 관측값에 대한 레이블을 알고 있기 때문에 군집성공에 대한 정확도 파악 가능
- 하지만, 레이블이 없는 데이터의 경우 실루엣 계수와 엘보우 그래프(SSE) 를 통해 적절한 군집 계수를 파악해야 함
- 실루엣 계수 : 군집 적합도를 수치로 나타낸 것으로 1에 가까울수록 군집이 잘된 것으로 파악
- 엘보우SSE 계수 : 군집내 오차제곱합을 의미
from sklearn.metrics import silhouette_score
silhouette_score(data, kms.labels_, metric='euclidean')0.5528190123564095kms.inertia_78.851441426146### 적절한 군집 갯수 찾기
sss, els = [], []
for k in range(2, 10 + 1):
kms = KMeans(n_clusters=k, random_state=2208301540)
kms.fit(data)
ss = silhouette_score(data, kms.labels_, metric='euclidean')
el = kms.inertia_
sss.append(ss)
els.append(el)plt.plot(range(2, 10+1), sss, 'ro--')
plt.show()
plt.plot(range(2, 10+1), els, 'ro--')
plt.show()
분류 시각화 결과 - sepal length/sepal width
plt.scatter(data[:, 0], data[:, 1], c=target)
plt.show()
군집 시각화 결과 - sepal length/sepal width
kms = KMeans(n_clusters=3)
kms.fit(data)KMeans(n_clusters=3)On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KMeans(n_clusters=3)# cluster_centers_ : 군집의 중심점을 의미하는 좌표
kms.cluster_centers_array([[5.9016129 , 2.7483871 , 4.39354839, 1.43387097],
[5.006 , 3.428 , 1.462 , 0.246 ],
[6.85 , 3.07368421, 5.74210526, 2.07105263]])# 군집 중심 좌표 중 sepal length/sepal width 추출
centers = pd.DataFrame(kms.cluster_centers_)
centers.columns = ['sl', 'sw', 'pl', 'pw']
x, y = centers.sl, centers.swplt.scatter(data[:, 0], data[:, 1], c=kms.labels_)
plt.scatter(x, y, marker='X', c='r') # 중심점 centernoid 표시
plt.show()
분류 시각화 결과 - sepal length/sepal width
plt.scatter(data[:, 2], data[:, 3], c=target)
plt.show()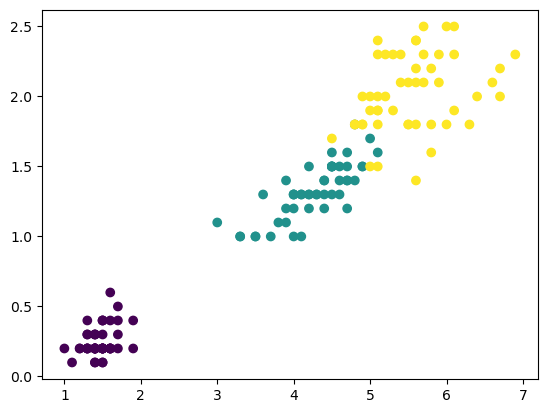
# 군집 중심 좌표 중 petal length/petal width 추출
x, y = centers.pl, centers.pwplt.scatter(data[:, 2], data[:, 3], c=kms.labels_)
plt.scatter(x, y, marker='X', c='r') # 중심점 centernoid 표시
plt.show()
실루엣, 엘보우 시각화
- yellowbrick패키지의 KElbow/Silhouette visualizer 함수 이용
- scikit-yb.org
from yellowbrick.cluster import SilhouetteVisualizer
from yellowbrick.cluster import KElbowVisualizer# ax[행][열] : 그래프 출력 위치 지정
# https://matplotlib.org/stable/gallery/subplots_axes_and_figures/subplots_demo.html
fig, ax = plt.subplots(2, 3, figsize=(15, 8))
for i in [2, 3, 4, 5, 6, 7]:
km = KMeans(n_clusters=i, random_state=2211221505)
q, mod = divmod(i, 3)
visualizer = SilhouetteVisualizer(km, ax=ax[q-1][mod])
visualizer.fit(data)
km = KMeans()
# visr = KElbowVisualizer(km, k=(2,7))
# visr = KElbowVisualizer(km, k=(2,7), timings=False)
visr = KElbowVisualizer(km, k=(2,7), metric='calinski_harabasz', timings=False)
visr.fit(data)
visr.show()

<AxesSubplot:title={'center':'Calinski Harabasz Score Elbow for KMeans Clustering'}, xlabel='k', ylabel='calinski harabasz score'>728x90
'PYTHON > 데이터분석' 카테고리의 다른 글
| [머신러닝-비지도] 04. Hierarchical clustering (0) | 2023.01.04 |
|---|---|
| [머신러닝-비지도] 03. dendrogram (0) | 2023.01.04 |
| [머신러닝-비지도] 01. 군집분석 (0) | 2023.01.04 |
| [머신러닝] 17. 부스팅(boosting) (0) | 2023.01.03 |
| [머신러닝] 16. 랜덤 포레스트 (0) | 2023.01.03 |
'PYTHON/데이터분석' Related Articles
more




Comments